

进度赶超大厂,中国最接近Sora的视频模型出自一家“清华系”公司
进度赶超大厂,中国最接近Sora的视频模型出自一家“清华系”公司
文|周鑫雨
编辑|苏建勋
" 镜头围绕一大堆老式电视旋转,所有电视都显示不同的节目—— 20 世纪 50 年代的科幻电影、恐怖电影、新闻、静态、1970 年代的情景喜剧等,背景设置在纽约一家大型博物馆画廊。"
若这是对视频剪辑师的一道命题作业,复杂的细节和叠加的图层也定会让不少人叫苦不迭。曾有专业剪辑师测试过,若是用公开素材剪出一段符合基本要求的 5 秒视频,大概要花费 1-2 小时。

来源:网络
而这句 " 地狱提示词 ",也被业界视作视频生成模型的试金石。近期,在这一句提示词下,诞生了两段视频:

1

2
前者,想必不少读者并不陌生,出自 OpenAI 的现役视频生成模型天花板,于 2024 年 2 月发布的 Sora 之手。相对地,后者在满足画廊的环境、播放着各种老片的电视机等基本元素的要求上,还增加了机位的连续变动,让视频更加丰富。
这段敢在关公前耍大刀的视频,来源于一个名叫 "Vidu"(谐音 We do)的文生视频模型,并且,当大多国内厂商仍在为突破 4 秒瓶颈时,Vidu 已经将国产文生视频模型的生成时长天花板,拉到了16 秒。
这匹国产文生视频模型界的 " 黑马 ",来自成立于 2023 年的 " 清华系 "AI 公司 " 生数科技 "。在 2024 年 4 月 27 日举办的中关村论坛上,完成首秀的 Vidu 得到了在场不少人 " 很接近 Sora" 的感叹。
在 Sora 发布之前,随着 Runway、Pika 等视频生成新秀的崛起,国内也早就掀起视频生成模型的竞速,主要玩家不仅包括 BTA 和字节跳动,还有前京东副总裁梅涛成立的 Hidream,以及前字节跳动 AI Lab 总监王长虎创办的爱诗科技。
16 秒的门槛有多难跨?可见的是,目前全球一次性视频生成能够达到该级别时长的 " 文生视频 " 模型,只有 OpenAI 的 Sora(60 秒)、Runway 的 Gen-2(18 秒),以及同为国内初创公司的 Hidream(15 秒)。
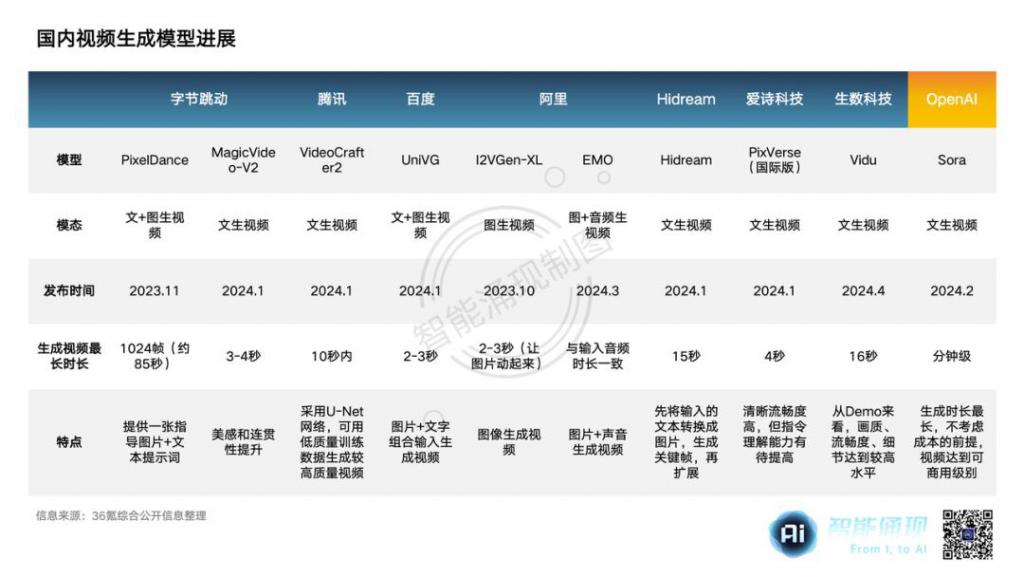
制图:36 氪
即便是人才和训练资源一骑绝尘的大厂,想要生成超过 10 秒的长视频,或要辅以图片、音频等其他模态的输入(如 PixelDance 和 EMO),或需要先将文字提示词生成为图片关键帧,再利用图片生成连续视频(如 Hidream)。
这对剪辑师和创作者而言,生成的质量提高有限,反倒让工具的使用门槛高了不少,得不偿失。
而 " 国产 Sora"Vidu 的出现,给苦找素材、作息 007 的剪辑打工人们,些许解放双手和大脑的希望。

多维度对标 Sora,但比 Sora 更懂中国风
被外界称为中国的 "Sora",生数科技也毫不避讳 Vidu 对 Sora 的对标。论坛上,生数科技发布的几个视频 Demo,用的是 Sora 同款提示词,对标的也是 Sora 最为出众的几个能力:
模拟真实物理世界、想象力、多镜头语言、时空一致性。
首先,为了展示模拟真实物理世界的程度,在 Vidu 中输入的是 Sora 同款提示词:
提示词:镜头跟随在一辆白色复古 SUV 后面,它带着黑色的车顶架,在陡峭的山坡上,沿着松树环绕的陡峭土路加速行驶,轮胎上扬起灰尘,阳光照在 SUV 上,它沿着土路飞驰,投射出温暖的光芒。土路缓缓地向远处弯弯曲曲,看不见其他车辆。道路两旁的树木是红杉,点缀着一片片的绿色植物。从后面可以看到赛车轻松地沿着弯道行驶,使它看起来像是在崎岖的地形上行驶。这条土路本身被陡峭的山丘和山脉环绕,上面是清澈的蓝天和缕缕云彩。
根据这段充盈着复杂物理世界细节的提示词,前者为 Sora 生成的一段视频,后者则是 Vidu 交的作业。在画质、光影细节等层面,两者几乎难分伯仲。

△ Sora 生成的视频

△ Vidu 生成的视频(由于上传大小限制,处理成 GIF 时对画质有所压缩)
而在虚构场景和超现实画面的能力上,Vidu 根据提示词 " 画室里的一艘船驶向镜头 ",也生成了一段富有视觉冲击力的视频。

△ Vidu 生成的视频
若要视频生成模型能在各领域商用,画质和细节是基本功,生成镜头是否足够复杂、动态也至关重要。下文的提示词,包含了长镜头、中远近景、特写以及追焦等效果,Vidu 生成的视频也能做到。
提示词:在一个古色古香的海边小屋里,阳光沐浴着房间,镜头慢慢过渡到一个阳台,俯瞰着宁静的大海,最后镜头定格在漂浮着大海、帆船和倒影般的云彩。

在镜头的连贯性和时空一致性上,Vidu 也能准确理解 3D 物体在现实中的时空维度。比如这一生成案例:
提示词:这是一只蓝眼睛的橙色猫的肖像,慢慢地旋转,灵感来自维米尔的《戴珍珠耳环的女孩》,画面上戴着珍珠耳环,棕色头发像荷兰帽一样,黑色背景,工作室灯光。

不过,也有不少用户发现,Vidu 展示的 Demo 视频中,出现的大多是西方面孔。这也让 Vidu 身陷 " 是否套壳国外开源视频模型 " 的争议。对此,生数科技告诉 36 氪,这是由于 Vidu 训练数据中的面孔数据中,西方面孔占据大多数所致。
生数科技联合创始人兼 CEO 唐家渝曾对 36 氪表示,生数科技多模态模型的训练数据主要来源于两块:互联网上大量公开的数据,通过向版权方购买的私有数据,两者共同完善训练数据的丰富性。而从全球来看,互联网上的公开视频数据,依然以西方主题为主。
同样是训练数据的差异性使然,在对熊猫、龙等中国元素的理解上,Vidu 相较于 Sora 等海外模型更胜一筹。

△ Vidu 生成的视频(上图为龙、熊猫两段 Demo 片段拼接而成)
不到 2 个月,4 秒到 16 秒
将生成视频的时长从 4 秒抬到到 16 秒,美国 AI 独角兽 Runway 花了 4 个月,Vidu 背后的生数科技只用了 2 个月。
在 2024 年 3 月中旬的交流中,生数科技联合创始人兼 CEO 唐家渝对 36 氪表示,团队自研的多模态通用大模型,尚且初步具备了短视频的生成能力。发布的视频 Demo,时长也基本在 2-4 秒。
但相对地,Runway 是融资总额约 2.4 亿美元的明星独角兽,而生数科技的融资总额才不过数亿元。
要与资源与实力兼具的强者扳手腕,生数科技的手上也必须有几把刷子。
作为 " 清华系 " 的企业,多模态方面的技术储备自然是生数的门面。虽然采用与 Sora 相似的 Diffusion Transformer 融合架构,但 Vidu 的底层技术,则是生数团队原创研究的成果,甚至比 Sora 的底层架构发布得更早——
2022 年 9 月,生数科技就发布了 9.5 亿参数规模的 U-ViT 网络架构,这也是全球首个 Diffusion Transformer 架构。1 个月后,Stable Diffusion 才发布了初代 DiT 架构 U-Net,后被应用于 Sora 的研发。
另一把刷子,往往是一家企业的商业化能力。但视频生成模型至今难以大规模落地的原因就在于:太贵了!
投资机构 Factorial Funds 曾对 Sora 的成本做了一番推算:Sora 每生成一段视频的计算成本约为 708 × 10^15 FLOPS。换算下来,生成 1 分钟的视频大概需要 8 块英伟达 A800 计算 3 小时,成本约 60-90 美元,视频每秒产生的成本就在 1 美元左右。
唐家渝也曾对 36 氪坦言,长视频生成需要高昂的入场费,A100、A800 的卡可能要上万张。
这意味着,视频模型的技术迭代需要烧钱,落地应用后,用户的使用也会带来巨额的计算成本。视频模型厂商需要快速找到可以覆盖计算和推理成本的落地场景和商业模式。

生数科技的想法是:先在付费能力强和成本相对可控的 B 端场景落地。" 广告、短视频目前是比较直接的(落地场景),中期来讲我们比较看好游戏和电影娱乐形式的融合。" 生数科技方对 36 氪回应。
当然,从长远来看,视频模型的较量,绝对不只是各家公司之间的技术竞速。AI 界 " 教父 "OpenAI,已经在视频生成模型中,摸到了通往 AGI 的方向。
近日,Sora 团队的三位负责人在节目 "No Priors" 中表示,Sora 通过在神经网络中对复杂环境进行模拟,可以逐渐弥合当前 AI 和 AGI(通用人工智能)之间的差距。随着训练数据量和参数量的不断扩大,Sora 将有可能成为真正的世界模型。
在当下,视频生成模型也有更为现实的妙用:为多模态模型生成稳定、高质的训练数据。
比如近期,国内另一家学院派多模态模型公司——中国人民大学高瓴人工智能学院教授卢志武创立的 " 智子引擎 ",在中关村论坛上推出了 MoE(混合专家架构)多模态大模型 Awaker 1.0。
特别的是,用于 Awaker 1.0 训练的视觉数据,主要来源于智子引擎在 2023 年 5 月推出的自研视频生成底座 VDT,一个同样采取 Transformer Diffusion 架构的模型。卢志武在论坛上表示,未来更加通用的 VDT 将成为解决多模态大模型数据来源问题的得力工具。使用视频生成的方式,VDT 将能够对现实世界进行模拟,进一步提高视觉数据生产的效率。

△ VDT 生成的写真视频(上图为多段 Demo 片段拼接而成)
当然,在 16 秒时长的赛道,生数科技已经用 Sora 同款架构,闯出了名堂。但接下来,无论是商业化的验证、商业模式的设计,以及跨越 16 秒到分钟级的时长门槛,对国内的 " 生数科技们 " 而言,都是需要相互竞速的考验。
New Things 是智能涌现一档围绕 AI 产品 / 应用的专栏,我们会聚焦最新、最火、最好玩儿的 AI 产品 / 应用,如果你有好玩的 AI 体验,也欢迎推荐给我们。

欢迎交流!
-
- 盘点邢台十大免费景区 人少景好值得一去!
-
2024-12-10 19:00:57
-

- 谁才是中华民族的人文初祖?其实并不止炎黄二帝,你知道还有谁?
-
2024-12-10 18:58:42
-
- 热门小说《全球高武》人物介绍
-
2024-12-10 18:56:27
-

- 赶紧学会!传承50年的养花绝招,即将失传!
-
2024-12-10 18:54:12
-
- "人善被欺"宋小宝:被错认成小沈阳,怒摔话筒愤然离席吓傻所有人
-
2024-12-10 18:51:56
-

- 伊莎贝拉女王:西班牙帝国的奠基者
-
2024-12-10 18:49:41
-

- 中国的十大世界之最,作为一名中国人都需要知道,你知道几个?
-
2024-12-10 18:47:26
-
- 你的生命有什么可能
-
2024-12-10 18:45:11
-

- 网友:以后我不要再养“萨摩耶”了,原因有6个
-
2024-12-10 04:25:23
-

- 万水千山,最美中国道路《不忘初心》曲调悠扬,歌词暖心
-
2024-12-10 04:23:08
-
- 太原市交警通报24处电动自行车上牌点具体地址
-
2024-12-10 04:20:53
-
- 台北故宫博物院
-
2024-12-10 04:18:38
-

- 秦时明月:佩戴天下第一剑的嬴政是高手吗?他能否打败剑圣盖聂?
-
2024-12-10 04:16:22
-

- 猫咪老喜欢躲在床底下?原因有这些
-
2024-12-10 04:14:07
-

- 麻杏石甘汤:中医健康宝典中的神奇方剂
-
2024-12-10 04:11:52
-

- 格雷森·阿伦(Grayson Allen)
-
2024-12-10 04:09:37
-

- “破窗理论”的启示
-
2024-12-10 04:07:21
-
- 中国高铁兰渝铁路“南充北站”(高铁游)
-
2024-12-10 04:05:06
-

- 怎样挽回失去的爱情?
-
2024-12-10 04:02:51
-

- 演员奚望:在继父刘之冰支持下离婚后,带着女儿的她,现在怎样了
-
2024-12-10 04:00:36
 日本男演员影响力榜单TOP10出炉!第一名果然是他……
日本男演员影响力榜单TOP10出炉!第一名果然是他…… 玩腻了是什么意思
玩腻了是什么意思 榄菊是什么植物
榄菊是什么植物 想要明目张胆的偏爱什么意思
想要明目张胆的偏爱什么意思 张耀什么学校毕业
张耀什么学校毕业 网购是从什么时候开始的
网购是从什么时候开始的 组歌是什么意思
组歌是什么意思 淞沪会战
淞沪会战 红色传承 - 重庆红色培训基地(7):重庆抗战遗址博物馆
红色传承 - 重庆红色培训基地(7):重庆抗战遗址博物馆 「新年快乐」新年超萌头像第二弹!80个头像,一天一个不重样
「新年快乐」新年超萌头像第二弹!80个头像,一天一个不重样